Passmark Found a Bug Playwright Would Have Missed
The AI caught a bug my Playwright tests would have ignored
🚀 Passionate about cloud and DevOps, I'm a technical writer at Hasnode, dedicated to crafting insightful blogs on cutting-edge topics in cloud computing and DevOps methodologies. Actively seeking opportunities in the DevOps domain, I bring a blend of expertise in AWS, Docker, CI/CD pipelines, and Kubernetes, coupled with a knack for automation and innovation. With a strong foundation in shell scripting and GitHub collaboration, I aspire to contribute effectively to forward-thinking teams, revolutionizing development pipelines with my skills and drive for excellence.
#DevOps #AWS #Docker #CI/CD #Kubernetes #CloudComputing #TechnicalWriter
I maintain the entire stack for a live SaaS platform solo. Infra, backend, CI/CD, deployments. When something breaks at 2am, it's on me.
The part that quietly kills solo engineers isn't the deployments or the incidents. It's the test maintenance. You write a Playwright test, it works, a frontend engineer renames a class three months later, and now your CI is red. You dig into a selector that made sense when you wrote it and has zero context now. You fix it. It breaks again next sprint.
I've been living this cycle. So when I heard about Passmark — write tests in plain English, AI figures out the selectors — I didn't want to read the docs. I wanted to run it on a real app and see what actually happens.
I used it on demo.vercel.store, the open-source Next.js Commerce demo by Vercel. 8 tests covering the full shopping flow. First run took 8.2 minutes. Three tests failed. One failure caught a real bug in the app that a normal Playwright test would have passed right through.
Here's the full story.
The missing piece in AI-assisted development
Everyone's talking about AI for writing code. Cursor, Claude Code, Copilot. You describe what you want, the agent writes it.
But nobody's talking about what happens after the code ships. Tests still break on every UI change. Selectors still rot. Someone still has to maintain them.
That's the gap Passmark is trying to close. You describe what to test in plain English. AI runs it in the browser using Playwright. It caches every browser action to Redis on the first run. Every run after that replays from cache at native Playwright speed, no AI calls. When a UI change breaks a cached action, the AI re-discovers the correct interaction automatically and updates the cache.
The idea is: write the test once in plain English, never touch it again even when the UI changes.
That's a bold claim. I wanted to see it under real conditions.
How Passmark compares to writing Playwright tests by hand
Here's the same "add to cart" test written both ways.
Traditional Playwright:
test("add product to cart", async ({ page }) => {
await page.goto("https://demo.vercel.store");
await page.locator('[data-testid="product-link"]').first().click();
await page.locator('[aria-label="Select color White"]').click();
await page.locator('[aria-label="Select size Small"]').click();
await page.locator('[data-testid="add-to-cart"]').click();
await expect(page.locator('[data-testid="cart-count"]')).toHaveText("1");
});
Passmark:
test("add product to cart", async ({ page }) => {
test.setTimeout(120_000);
await runSteps({
page,
userFlow: "Add to cart",
steps: [
{ description: "Navigate to https://demo.vercel.store" },
{ description: "Click on the Acme Circles T-Shirt product" },
{ description: "Select color White" },
{ description: "Select size Small" },
{ description: "Click Add to Cart button" },
],
assertions: [
{ assertion: "Cart opens or updates showing the Acme Circles T-Shirt" },
{ assertion: "The cart shows a quantity of 1" },
],
test,
expect,
});
});
The traditional version is brittle by design. data-testid="product-link" exists until a developer removes it. aria-label="Select color White" breaks the moment someone changes the label format. The test is tied to implementation details, not user behavior.
The Passmark version describes what a user does. It doesn't care how the button is implemented. If the UI changes, the AI re-discovers the correct interaction and updates the cache. You don't touch the test file.
The tradeoff is speed on first run. The AI needs time to discover and execute each step. That's the 8 minutes I mentioned. Subsequent runs are fast because they replay from Redis cache. For a CI pipeline that runs on every push, you'd persist the Redis data between runs and pay the discovery cost only once.
Setup: one thing the docs don't emphasize enough
The official setup is straightforward: create a Playwright project, install Passmark, add your OpenRouter or any other LLM API key to the .env file, and configure the gateway.
// playwright.config.ts
import { defineConfig, devices } from "@playwright/test";
import dotenv from "dotenv";
import path from "path";
import { configure } from "passmark";
dotenv.config({ path: path.resolve(__dirname, ".env") });
configure({
ai: {
gateway: "openrouter",
},
});
export default defineConfig({
testDir: "./tests",
timeout: 120_000,
fullyParallel: false,
workers: 1,
use: {
baseURL: "https://demo.vercel.store",
},
projects: [
{
name: "chromium",
use: { ...devices["Desktop Chrome"] },
},
],
});
What the docs understate is Redis. Without Redis, every single run goes through the AI with zero caching. The warning is easy to miss:
WARN (passmark-ai): REDIS_URL not set. Step caching, global placeholders,
and project data are disabled.
I had Redis running as a systemd service on my machine. I had REDIS_URL=redis://localhost:6379 in my .env. The warning kept showing up anyway.
The issue is that Passmark reads REDIS_URL from the shell environment, not just from dotenv. The fix is to export it directly if warning shows again:
echo 'export REDIS_URL=redis://localhost:6379' >> ~/.bashrc
source ~/.bashrc
After that, the warning was gone. The confirmation that Redis was actually being used came when I stopped the Redis service mid-run to test something. The tests immediately threw TCP connection errors. It was connected the whole time. The env variable just wasn't being picked up by the child process correctly until I exported it at the shell level.
For CI, spin up Redis as a service container alongside your test job:
jobs:
test:
runs-on: ubuntu-latest
services:
redis:
image: redis
ports:
- 6379:6379
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: lts/*
- run: npm ci
- run: npx playwright install --with-deps chromium
- name: Run tests
env:
OPENROUTER_API_KEY: ${{ secrets.OPENROUTER_API_KEY }}
REDIS_URL: redis://localhost:6379
run: npx playwright test --project=chromium
Redis available on localhost:6379 inside the job automatically. No extra configuration.
The 8 tests I wrote
I covered five areas of the Vercel Commerce demo: homepage loading and navigation, product detail page, variant selection, cart behavior, search, and checkout flow.
Nothing exotic. These are the flows that matter in any e-commerce app. Add to cart, select a variant, get to checkout. If these break, the business breaks.
Full test suite is on GitHub: passmark-vercel-commerce-tests


First run: 3 failures, one of them genuinely interesting
Failure 1 and 2: Timeouts
The cart item count test and the checkout test both hit the 120 second timeout. The cart test navigated back to the homepage after adding an item and validation took longer than expected across the navigation. Checkout redirects to Shopify's hosted checkout which adds real latency.
Both fixed by bumping the timeout to 180 seconds and simplifying the cart test to validate the cart state without navigating away first. Standard stuff for anyone who's written Playwright tests against apps with external redirects.
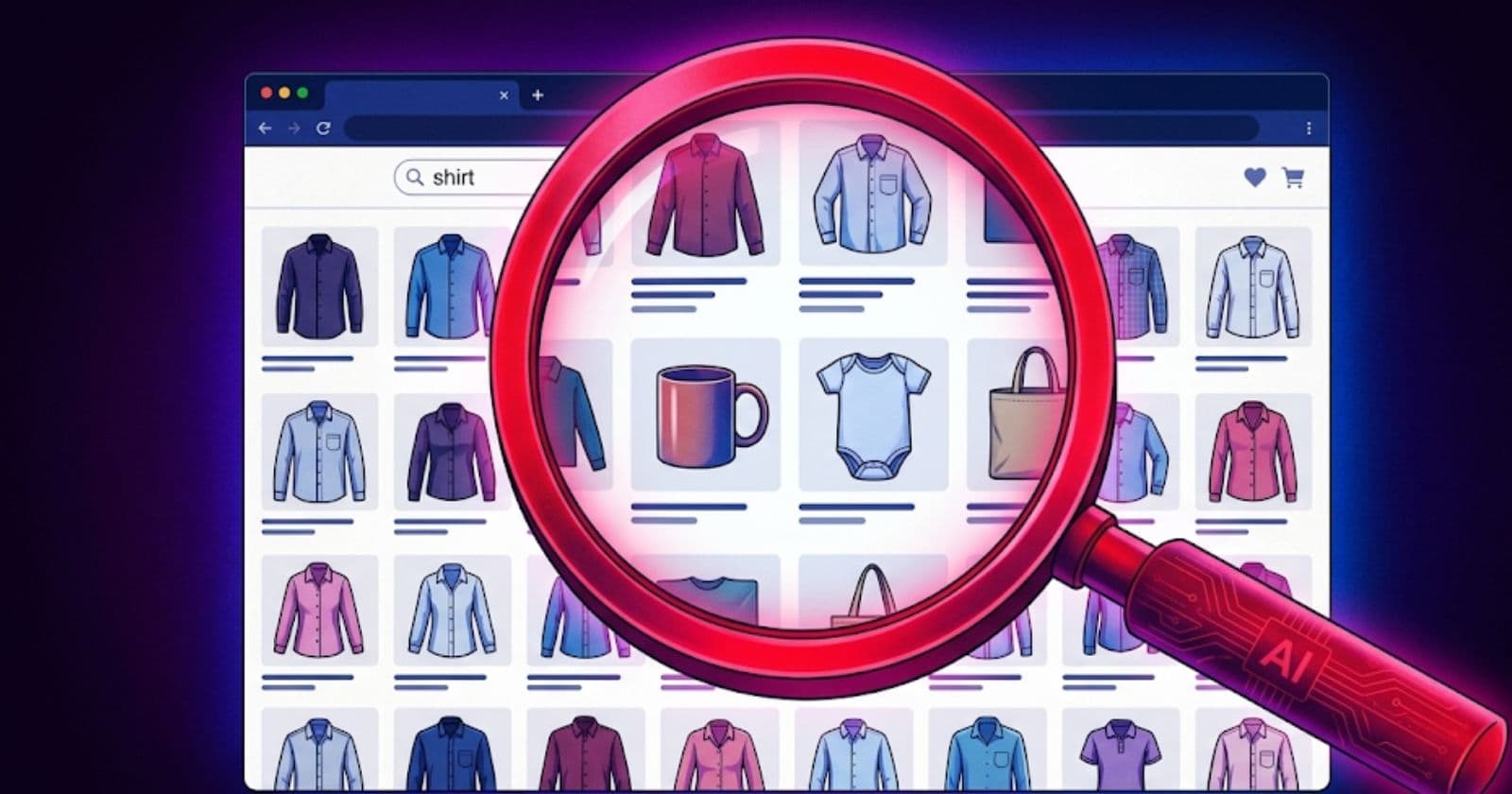
Failure 3: The search test
This one is different. The assertion was:
Results are relevant to the search term shirt
Passmark failed it. Here's the exact error:
The search term is 'shirt'. While the first result is a T-Shirt,
the subsequent results include a drawstring bag, a cup, a mug,
a hoodie, a baby onesie, and a baby cap. Because the majority
of the displayed results are not shirts, the search results as
a whole are not relevant to the search term.
Read that again. The AI looked at every search result on the page, evaluated each one against the search term, reasoned about the majority, and failed the assertion because most results were irrelevant.
A traditional Playwright test for this would look something like:
const results = page.locator('[data-testid="search-result"]');
await expect(results).toHaveCountGreaterThan(0);
That test passes. Results exist. Test is green. Nobody notices that searching for "shirt" returns a mug and a baby onesie.
Passmark evaluated relevance the way a user would. The search on demo.vercel.store is genuinely bad. It returns loosely associated products across the entire catalog instead of matching on the search term. That's a real UX problem. Normal Playwright assertions would never catch it because they check for existence, not quality.
I updated the assertion to reflect reality:
assertions: [
{ assertion: "Search results are shown with at least one product visible" },
{ assertion: "The first result is related to the search term shirt" },
],
But the original failure is the finding worth keeping. If this were a production app, that search behavior would be silently degrading conversion rates. AI-powered assertions that reason about output quality instead of just checking element existence will catch things that selector-based tests structurally cannot.
The development speed angle
I build features fast because I'm the only person in the loop. No PR reviews slowing me down, no coordination overhead. The slowdown is test maintenance.
Every time I push a UI change, I'm mentally calculating whether any existing tests will break. If I change a component's structure, I'm opening test files and hunting for selectors that reference it. That mental overhead accumulates.
With Passmark, that calculation changes. The tests describe user behavior. The AI handles the implementation details. When I change how a button renders, the test doesn't care. It still says "Click Add to Cart button" and the AI figures out where that button is now.
That's the actual development speed improvement. Not the test writing time, which is roughly the same. It's the maintenance overhead that disappears.
The first run cost of 8 minutes is real. For a solo engineer running tests locally before pushing, that's too slow for every commit. The practical workflow is: run Passmark tests on the CI pipeline for the critical paths, use fast unit tests locally. Let the AI-powered smoke tests catch regressions on merge.
Where this fits in a real pipeline
I wouldn't replace my entire test suite with Passmark today. The first run timing, the Redis persistence question in CI, the per-run AI cost on assertions — these are real constraints.
What I'd do: pick the 5-8 flows where a regression would be catastrophic. For an e-commerce app, that's add to cart, checkout, payment confirmation. For my production app, it's the booking flow, the payment flow, the auth flow. Write Passmark tests for exactly those. Let them run on every PR in CI. Pay the AI cost on assertions because catching a broken checkout before it hits production is worth it.
The self-healing on UI changes is where Passmark earns its keep long term. When your frontend evolves, the tests don't become tech debt. They stay current automatically. For a solo engineer who doesn't have time to babysit test files, that's the real value.
If you're already running Playwright and want to try this without committing to a full migration, start with one critical flow. Add it to your existing config, it works alongside your current tests. See how the assertion quality compares to what you're writing today.
The search relevance failure convinced me this approach finds things that traditional assertions miss. That's enough to keep it in my toolbox.



